

Into Parallel Architectures - Part 1


In the realm of parallel computing, Amdahl's Law stands as a guiding principle, reminding us that even with an infinite number of processors, certain portions of a program remain stubbornly sequential. As we journey deeper into the intricacies of parallel architecture, let's peer into a hypothetical scenario where the boundless potential of processors meets the constraints of this fundamental law.
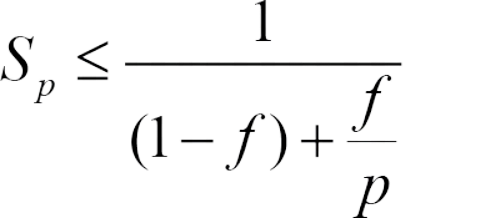
Think of a world with lots of computer helpers ('P'). They can do tasks super fast together. But there's a rule called Amdahl's Law that says even with all these helpers, some tasks can't be speeded up ('f'). If 'f' is just 2%, then no matter how many helpers ('P') we add, we can't make things more than 50 times faster.
As we learn more about how computers work together, Amdahl's Law reminds us that there are always limits to how fast we can go, no matter how many helpers we have.
Flynn's Taxonomy:
In the realm of parallel computing systems, several essential components work in harmony to achieve efficient computation. These components include processors, memory (both private, belonging to individual processors, and shared, accessible to multiple processors), and the interconnects that facilitate communication between these processors.
Control is a crucial aspect of parallel architectures, governing how instructions operate on data. Flynn's taxonomy, a fundamental classification system, categorizes architectures based on their control characteristics. There are four primary categories within Flynn's taxonomy:
Types of Parallel Architectures:
Single Instruction Single Data (SISD): In this category, a single processor executes a single instruction on a single piece of data at any given moment. It's akin to a solo musician playing one note at a time—a sequential, non-parallel approach.
Multiple Instruction Single Data (MISD): While less common, MISD architecture involves applying multiple instructions to one piece of data. Think of it as having a group of chefs all working on a single dish using different recipes. This type of architecture is not widely used in practice.
Single Instruction Multiple Data (SIMD): SIMD architecture is more prevalent and is commonly used in high-performance computers. It's like having an orchestra play different pieces of music but using the same conductor's instructions. Here, a single instruction is applied to multiple pieces of data concurrently.
Multiple Instruction Multiple Data (MIMD): In MIMD systems, it's like having multiple chefs preparing various dishes in the same kitchen. Each chef follows their set of instructions and uses their data. This architecture offers flexibility and diversity and is widely used in modern computer systems.
These categories provide a fundamental framework for understanding the control and data flow in parallel computing architectures. In the journey through parallel architecture, exploring how these categories are applied in various systems unveils the dynamic and versatile world of high-performance computing.
How SIMD Architecture Works:
SIMD architecture simplifies programming by using a single instruction for all data. It consists of multiple execution units, each with its registers. This design minimizes replicated control, saving cost and power. However, some applications may require breaking down components for different units. During each clock cycle, every execution unit applies the same instruction, but conditional disabling allows only specific units to execute based on certain conditions. This architecture enables parallel execution but may result in more clock cycles for particular instructions.
Optimizing Code for Parallel Architectures:
Efficient code organization is vital in parallel systems to minimize processor idle time. Grouping work units where conditions are mostly evaluated as either all true or all false optimizes performance. Each processor has its local registers and memory with potentially varying offsets and data. While interconnections can vary, it's crucial to understand different types, including direct connections and indirect networks, which involve switches. Protocols manage data transfer, and buffering plays a role in the process.
Parallel Architecture in Action:
To understand how parallel architecture operates, consider an example like loading data from memory. Each processor has a base address and an index value. Processors load data from different memory locations based on their index values and accumulate results. Special instructions may support parallel processing, such as reading the processor ID. Despite variations, memory layout and reading from memory remain consistent for all processors.
Parallel architectures rely on efficient interconnects for data transfer. Two common categories include:
Direct Connections: Here, processors are directly linked via ports and wires for data exchange.
Indirect Networks: In these systems, switches mediate data exchange between processors.
Protocols and buffering mechanisms play crucial roles in managing data transfer efficiency. The choice between different interconnects depends on specific system requirements and scalability needs.
As we continue our exploration of parallel architecture, these concepts form the foundation for understanding how modern computer systems harness the power of parallelism to tackle complex tasks and elevate computing performance to new heights.